Capítulo 9 Amostragem Não-Probabilística
Atenção! Este capítulo está em fase de desenvolvimento. Visite a página do projeto se tiver alguma sugestão, dúvida ou estiver disposto a colaborar. Sua opinião/ajuda é muito importante!
Até agora, este capítulo contou com contribuições na forma de conteúdo intelectual e/ou revisões relevantes das seguintes pessoas:
9.1 Introdução
Na amostragem não-probabilística, como o próprio nome já diz, não são considerados os valores de probabilidade de inclusão para a seleção dos locais de amostragem. A escolha dos locais de amostragem depende da definição de um critério a ser atendido.
A amostragem não-probabilística costuma ser dividida em três categorias:
- casual,
- conveniente, e
- intencional.
9.2 Amostragem casual
Outros nomes:
Português: amostragem ao acaso, amostragem aleatória.
Inglês: haphazard sampling, random sampling.
Na amostragem casual os locais de amostragem são escolhidos, fundamentalmente, em função da subjetividade da pessoa conduzindo a amostragem. Não existe um critério claro a ser atendido. Outros locais amostrais podem ser escolhidos caso outra pessoa conduza a amostragem, mesmo que não haja justificativa plausível para isso. Assim, a amostragem causal deve ser evitada sempre que possível.
Na prática, a amostragem casual consiste em transitar pela área a ser amostrada e, aqui e acolá, definir um local para amostragem. Isso dá a impressão de que as observações são aleatórias, um pressuposto estatístico comum. Entretanto, supor que tais observações são aleatórias é um equívoco, dado que é impossível calcular as probabilidades de inclusão de cada amostra. É devido a esse comum equívoco que a expressão amostragem aleatória tem caído em desuso junto a comunidade estatística, dando-se preferência à expressão amostragem probabilística (veja acima).
main <- "Amostra casual (zigue-zague)"
plot(
meuse.grid@coords, type = "n", asp = 1, main = main,
xlab = "Longitude (m)", ylab = "Latitude (m)")
polygon(meuse.riv, col = "lightblue", border = "lightgray")
image(
meuse.grid, "soil", col = terrain.colors(3), axes = TRUE, add = TRUE)
legend(
"topleft", title = "Tipo de solo", fill = terrain.colors(3),
legend = c("Solo calcário", "Solo não-calcário", "Solo vermelho"),
border = terrain.colors(3), bty = "n")
text(179050, 331200, "Rio Meuse", srt = 50, cex = 0.7)
set.seed(2000)
pts <- sp::spsample(meuse.grid, n = 15, type = "nonaligned")
points(pts, pch = 21, cex = 0.75)
arrows(
meuse.grid@coords[1, 1], meuse.grid@coords[1, 2], pts@coords[length(pts), 1], pts@coords[length(pts), 2],
length = 0.1)
for (i in 2:length(pts) - 1) {
arrows(
x1 = pts@coords[i, 1], y1 = pts@coords[i, 2], x0 = pts@coords[i + 1, 1], y0 = pts@coords[i + 1, 2],
length = 0.1)
}
leg <- paste("Amostras (n = ", length(pts), ")", sep = "")
legend(176100, 332750, legend = leg, pch = 21, bty = "n")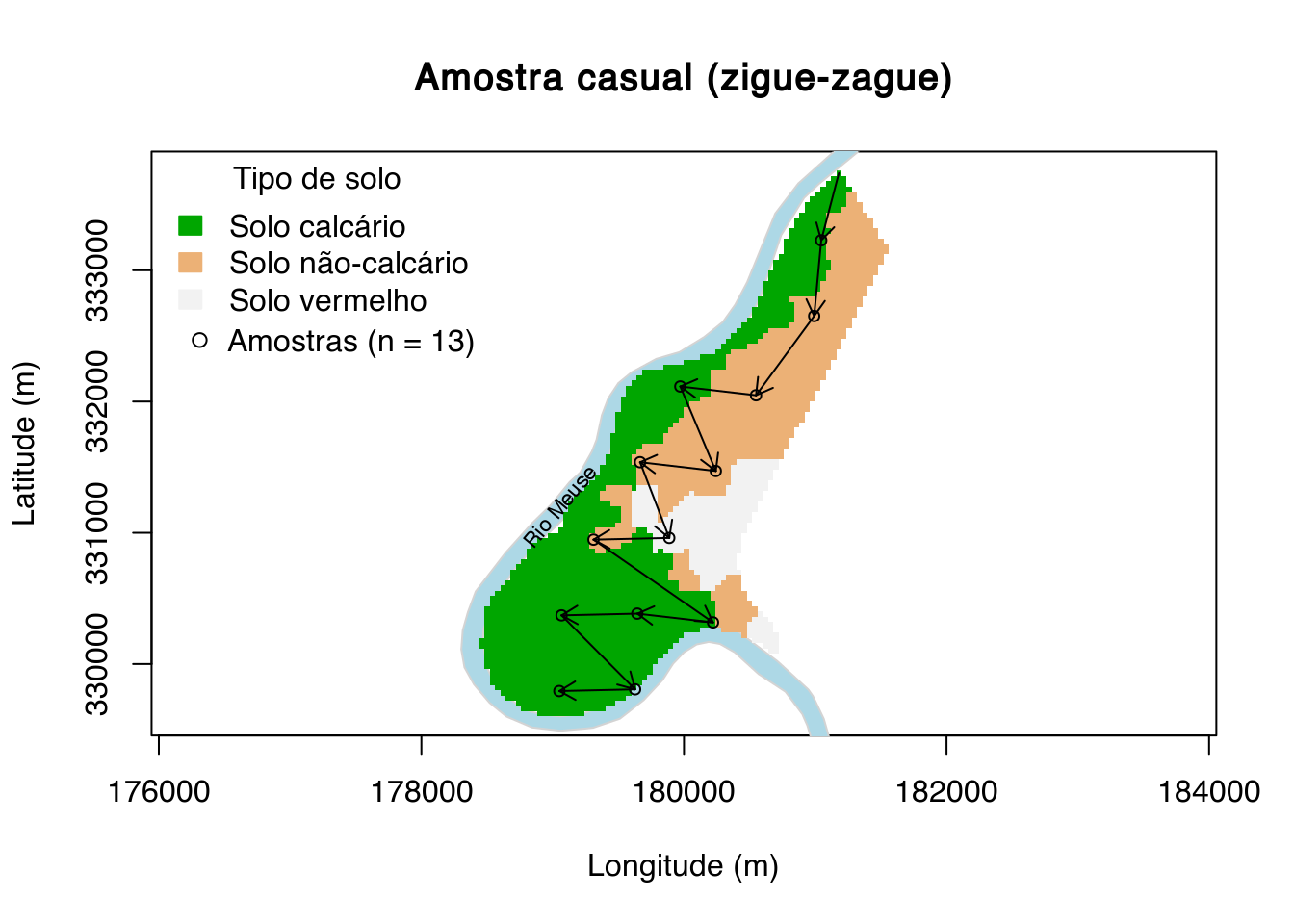
9.3 Amostragem conveniente
Outros nomes:
Português: amostragem por conveniência, amostragem por acessibilidade.
Inglês: convenience sampling, accessibility sampling.
A amostragem conveniente está diretamente relacionada à otimização do uso dos recursos disponíveis. Ela consiste em evitar realizar observações em locais de difícil acesso como áreas densamente florestadas, distantes de estradas, terrenos íngremes, ou áreas que apresentem risco para a saúde ou à vida devido à presença de, por exemplo, animais peçonhentos. Assim sendo, o critério usado para a definição dos locais de observação é a soma dos custos financeiro e operacional. Quanto menor forem os custos financeiro e operacional, maior será o número de observações.
O resultado da amostragem conveniente é a concentração das observações em áreas usadas para agricultura, próximo de estradas, nas bordas de florestas, e em terrenos não-montanhosos. Perfis de solo descritos e amostrados em cortes de estrada são resultado de amostragem conveniente. Nesse caso, o responsável pela amostragem usa os recursos que seriam necessários para abrir uma trincheira e descrever/amostrar um perfil para descrever/amostrar vários perfis usando os cortes de estrada.
O uso da amostragem conveniente exige assumir que a estrutura da variação espacial do solo pode ser representada pelas observações obtidas, por exemplo, ao longo de estradas. Em outras palavras, qualquer estrutura de variação espacial que não apareça ao longo das estradas é descartada. Em áreas de pequena complexidade pedológica e bem servidas por estradas, a amostragem conveniente tem grande chance de ser eficiente. Do contrário, a amostragem conveniente é incapaz de capturar a maior parte da estrutura variação espacial do solo. Isso porque estradas costumam ser construídas em posições elevadas da paisagem, com boa drenagem, como nos divisores de águas. As áreas de borda de florestas são fortemente influenciadas pelo uso da terra subjascente. E os terrenos não-montanhosos costumam ter solo com maior desenvolvimento em profundidade. O modelo preditivo calibrado com tais observações terá bom desempenho aqui, mas não no restante da área.
main <- "Amostra conveninte (distante da margem do rio)"
plot(
meuse.grid@coords, type = "n", asp = 1, main = main,
xlab = "Longitude (m)", ylab = "Latitude (m)")
polygon(meuse.riv, col = "lightblue", border = "lightgray")
image(
meuse.grid, "soil", col = terrain.colors(3), axes = TRUE, add = TRUE)
legend(
"topleft", title = "Tipo de solo", fill = terrain.colors(3),
legend = c("Solo calcário", "Solo não-calcário", "Solo vermelho"),
border = terrain.colors(3), bty = "n")
text(179050, 331200, "Rio Meuse", srt = 50, cex = 0.7)
pik <- ifelse(meuse.grid$dist < 0.4, 0.0001, 1)
pik <- sampling::inclusionprobabilities(pik, 50)
set.seed(2001)
pts <- sampling::UPmultinomial(pik) == 1
pts <- meuse.grid[pts, ]
set.seed(2001)
pts@coords <- pts@coords +
matrix(runif(prod(dim(pts@coords)), min = -0.5, max = 0.5), ncol = 2) *
meuse.grid@grid@cellsize
points(pts, pch = 21, cex = 0.75)
leg <- paste("Amostras (n = ", length(pts), ")", sep = "")
legend(176100, 332750, legend = leg, pch = 21, bty = "n")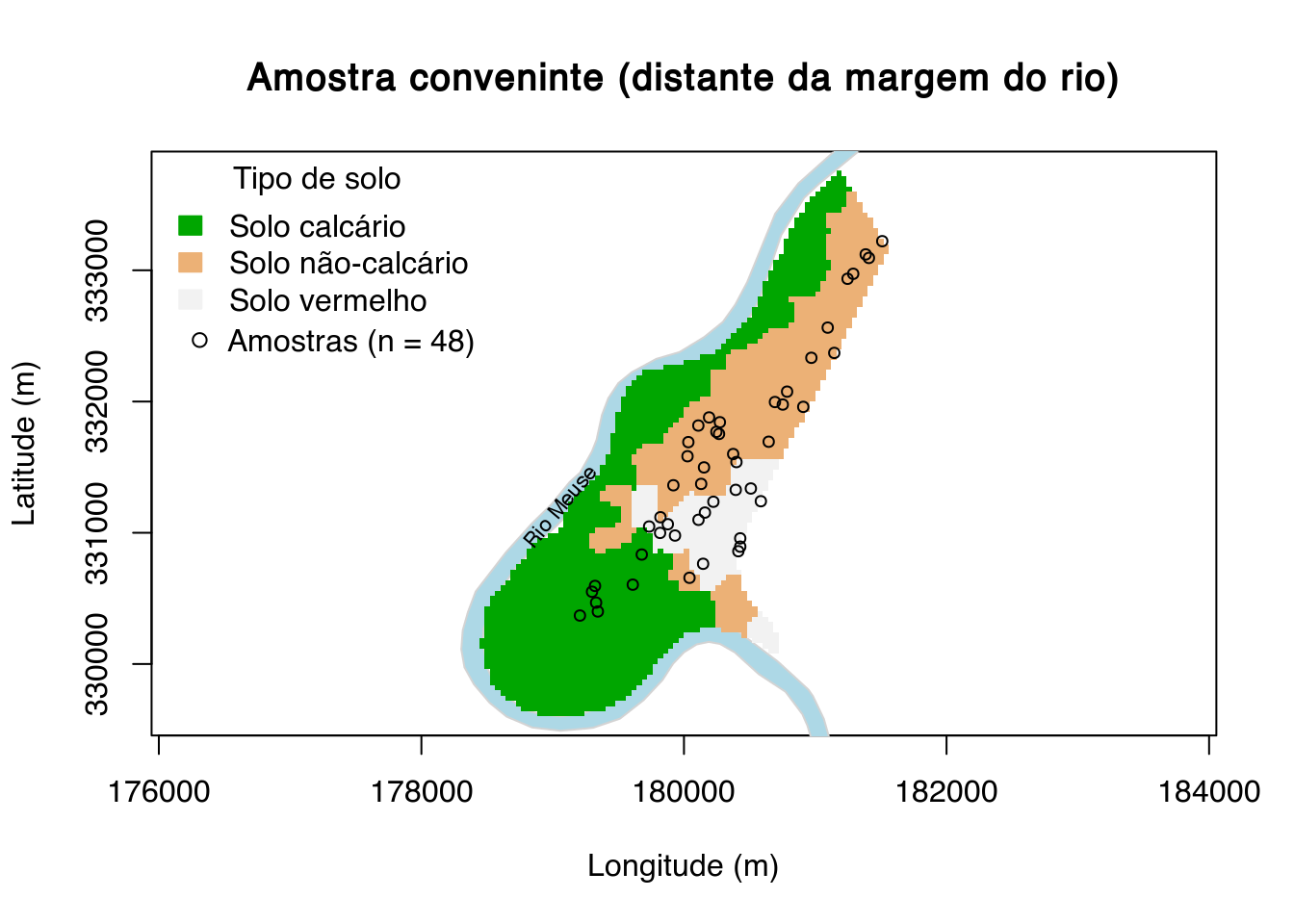
9.4 Amostragem intencional
Outros nomes:
Português: amostragem por julgamento.
Inglês: purposive sampling, judgement sampling, expert sampling, knowledge-based sampling.
A amostragem intencional é semelhante à amostragem conveniente no sentido de que em ambas os locais amostrais são definidos a fim de otimizar um critério pré-determinado. A diferença fundamental entre as duas é a natureza desse critério. Enquanto na amostragem conveniente o critério tem origem puramente econômica, na amostragem intencional o critério tem origem pedológica e/ou estatística, podendo-se agregar critérios de origem econômica.
Um critério pedológico e/ou estatístico tem origem no modelo usado para descrever a estrutura da variação espacial do solo e o método usado para fazer predições espaciais. Por exemplo, o objetivo pode ser selecionar os locais amostrais de maneira a obter a melhor cobertura espacial porque isso minimiza a incerteza das predições. O resultado disso seria uma amostra com observações equidistantes.
Em geral, a amostragem intencional é o tipo de amostragem mais eficiente para a obtenção de observações de calibração para a modelagem espacial do solo. Isso se dá exatamente porque a localização das observações é definida com base no modelo usado para descrever a estrutura da variação espacial do solo. Em outras palavras, a configuração espacial das observações é otimizada para atender aos pressupostos e requerimentos do modelo de distribuição espacial que será usado. Quanto mais conhecido for o modelo de distribuição espacial, tanto mais ótima será a configuração espacial das observações.
O método do caminhamento livre (em inglês, free survey), usado no mapeamento tradicional, utiliza-se da amostragem intencional. Aqui a localização das observações é definida com base no conhecimento tácito do responsável, seu modelo mental das relações solo-paisagem ou pedogênese. O modelo mental é construído com a experiência obtida no campo e sua qualidade geralmente é diretamente proporcional ao número de anos de trabalho de campo. É este modelo aquele usado para descrever a estrutura da variação espacial do solo.
Um dos critérios utilizados para a escolha dos locais de observação no método do caminhamento livre é a obtenção de uma amostra “representativa” das feições geomórficas, manchas de características do solo e usos da terra da área sendo mapeada. A localização das observações também costuma ser definida de forma a testar as hipóteses postuladas pelo responsável em função do seu modelo mental de pedogênese. Isso resulta em um grande número de observações concentradas na chamadas áreas-problema. As áreas-problema são aquelas para as quais o modelo mental de pedogênese é incompleto ou possui limitações significativas, ou seja, a variação espacial do solo é predita pobremente.
Outra forma de amostragem intencional é o uso de uma malha regular de pontos amostrais. Isso é comumente usado em trabalhos de mapeamento do solo para fins de agricultura de precisão, onde as características do solo costumam ser espacialmente homogêneas devido ao manejo agrícola. O objetivo principal não é a construção de um modelo para descrever a estrutura da variação espacial das propriedades do solo, mas sim obter predições com o menor erro possível usando métodos de interpolação como a krigagen. Quanto mais homogênea for a distribuição espacial das observações, menor será o erro de predição na área como um todo. Em outras palavras, o critério usado para otimizar a configuração espacial das observações é o erro de predição.
Um aspecto importante da amostragem intencional é que uma configuração espacial otimizada para um modelo de distribuição espacial geralmente será sub-ótimo para outro modelo de distribuição espacial. Por exemplo, uma configuração espacial otimizada para atender aos requerimentos de um modelo mental de pedogênese será sub-ótimo para um modelo estatístico, e vice-versa. O mesmo vale para dois modelos mentais de pedogênese ou dois modelos estatísticos diferentes. É nesse sentido que quanto mais conhecido for o modelo de distribuição espacial, tanto mais ótima será a configuração espacial das observações.
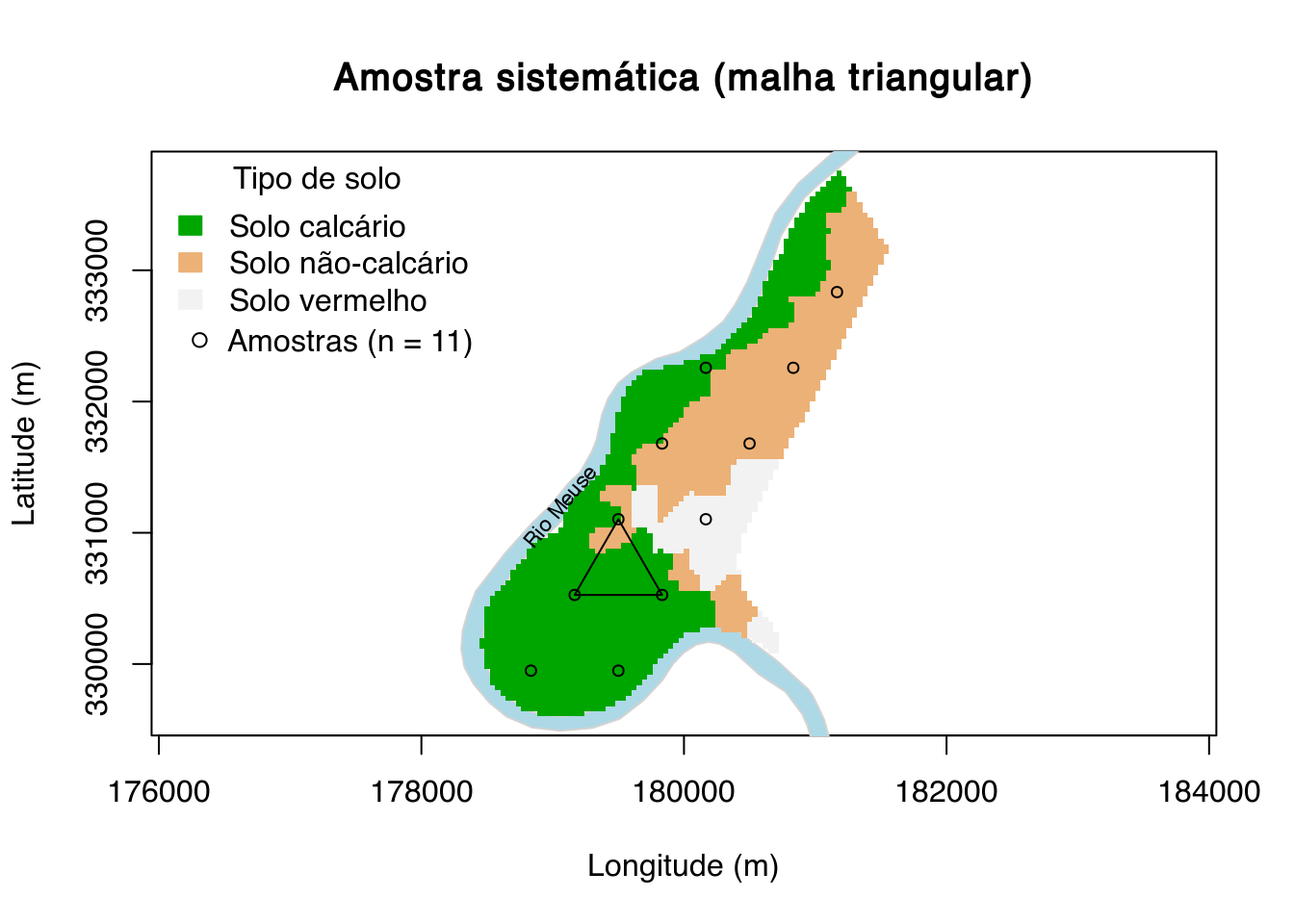
9.4.1 Amostragem sistemática
Outros nomes:
Português: amostragem em malha, amostragem em grid, amostragem geoestatística, amostragem para krigagem.
Inglês: systematic sampling, grid sampling.
main <- "Amostra sistemática (malha quadrada)"
plot(
meuse.grid@coords, type = "n", asp = 1, main = main,
xlab = "Longitude (m)", ylab = "Latitude (m)")
polygon(meuse.riv, col = "lightblue", border = "lightgray")
image(
meuse.grid, "soil", col = terrain.colors(3), axes = TRUE, add = TRUE)
legend(
"topleft", title = "Tipo de solo", fill = terrain.colors(3),
legend = c("Solo calcário", "Solo não-calcário", "Solo vermelho"),
border = terrain.colors(3), bty = "n")
text(179050, 331200, "Rio Meuse", srt = 50, cex = 0.7)
pts <- sp::spsample(meuse.grid, n = 15, type = "regular", offset = c(0.5, 0.5))
points(pts, pch = 21, cex = 0.75)
polygon(pts@coords[c(4, 5, 8, 7, 4), ])
leg <- paste("Amostras (n = ", length(pts), ")", sep = "")
legend(176100, 332750, legend = leg, pch = 21, bty = "n")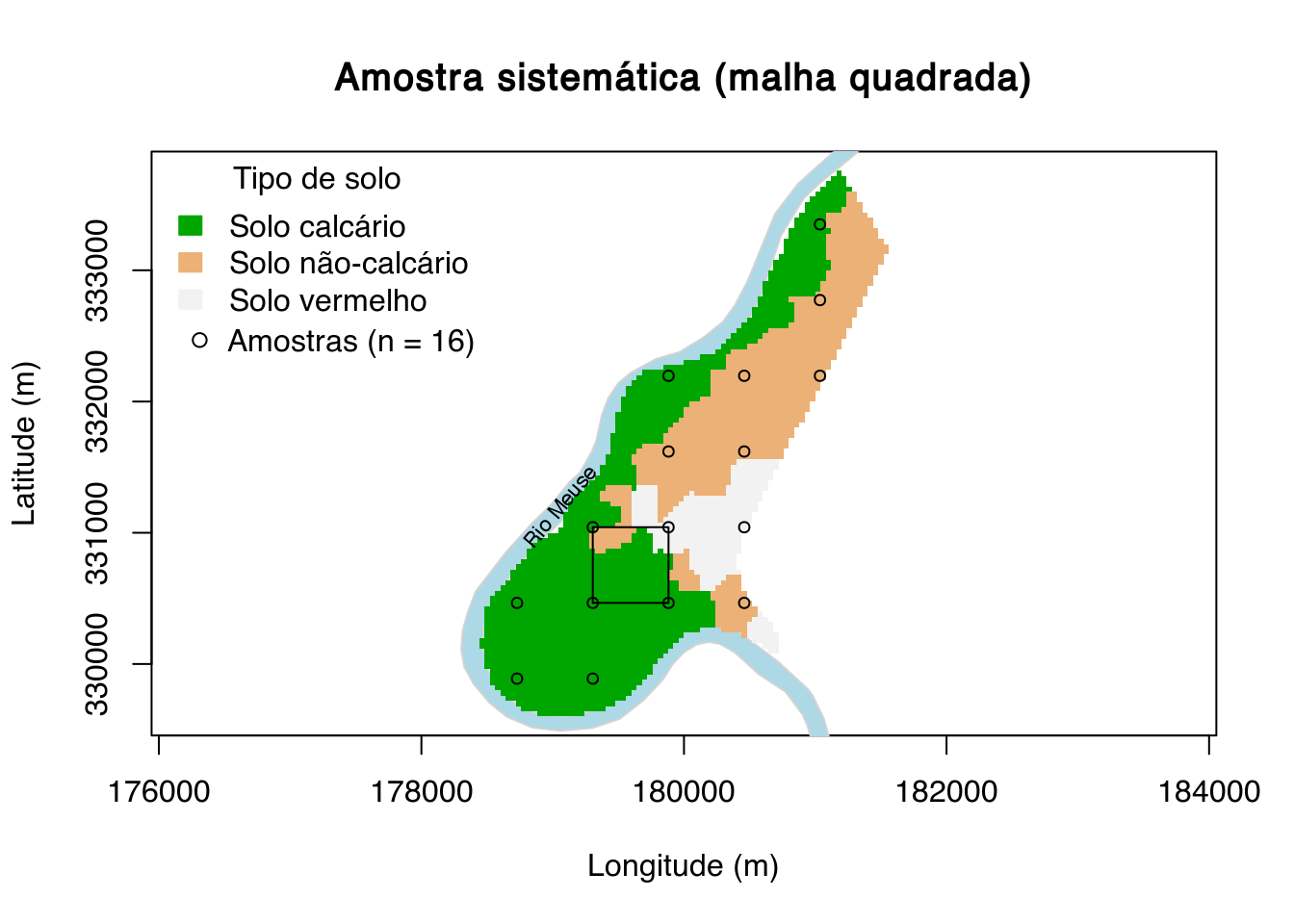
main <- "Amostra sistemática (malha triangular)"
plot(
meuse.grid@coords, type = "n", asp = 1, main = main,
xlab = "Longitude (m)", ylab = "Latitude (m)")
polygon(meuse.riv, col = "lightblue", border = "lightgray")
image(
meuse.grid, "soil", col = terrain.colors(3), axes = TRUE, add = TRUE)
legend(
"topleft", title = "Tipo de solo", fill = terrain.colors(3),
legend = c("Solo calcário", "Solo não-calcário", "Solo vermelho"),
border = terrain.colors(3), bty = "n")
text(179050, 331200, "Rio Meuse", srt = 50, cex = 0.7)
pts <- sp::spsample(meuse.grid, n = 15, type = "hexagonal", offset = c(0.5, 0.5))
points(pts, pch = 21, cex = 0.75)
polygon(pts@coords[c(3, 4, 5, 3), ])
leg <- paste("Amostras (n = ", length(pts), ")", sep = "")
legend(176100, 332750, legend = leg, pch = 21, bty = "n")